The Autonomous Therapist: AI that Writes Its Own Mental Health Strategies
Update: The Tier 5 / Run 3 Evolution (Constrained Decoding & Deterministic Scorer)



We have just deployed a major architectural refactor to launch Run 3 (Tier 5), addressing the infrastructure bottlenecks and scoring instabilities discovered in the previous runs.
Here are the key breakthroughs in this release:
Thinking Token Sanitization: We’ve enabled Gemma 4’s native <|think|> blocks to allow the “Scientist” agent to reason deeply before proposing new strategies, while automatically sanitizing those thought channels from the LangGraph message state to keep the conversation context window clean.
Grammar-Enforced Pydantic Schemas: By migrating to structured outputs (client.beta.chat.completions.parse()), the AI models are constrained at the grammar level to output valid Pydantic schemas, reducing JSON parse failure rates to 0%.
Native Tool-Calling: The patient’s somatic nervous system states (Sympathetic, Dorsal, Ventral Vagal) are now updated using native Ollama tool calls instead of fragile text parsing.
Deterministic Clinical Scorer: To eliminate grading hallucination and score drift, we replaced subjective LLM evaluation with a 100% deterministic Python scoring engine. It tracks somatic shifts and applies strict clinical heuristics (like Brevity, Third-Person references, and Grounding Cue checks).
Project Update: Moving to Somatic State-Spaces & Multi-Agent Orchestration
The autonomous self-improvement loop is leaving the realm of pure text and moving into the nervous system.
When this project started, the goal was to see if an AI could optimize its own words to deliver better cognitive therapy. But human breakthrough rarely happens just through logic; it happens when the nervous system settles into safety.
Here is what is currently cooking in the latest repo refactor:
- Tracking the Body, Not Just the Words: We’ve upgraded the simulated patient persona with a dynamic Somatic State-Space Engine. The simulation no longer just outputs dialogue; it tracks real-time shifts across three autonomic nervous system states: Sympathetic Hyper-arousal (Fight/Flight), Dorsal Vagal (Freeze), and Ventral Vagal (Safety/Grounded).
- The Single-Model VRAM Solution: Running multiple AI agents usually requires heavy cloud infrastructure or massive local hardware. To keep this strictly edge-native and private, the architecture has been refactored to run entirely on a single local 8B model. The code handles the heavy lifting by rapidly multiplexing—swapping the model’s internal “brain” between the Patient, Therapist, and Optimizer roles in millisecond intervals.
- Graduating to an Orchestra: We are officially moving away from a linear, rigid python script and restructuring the codebase into a true Multi-Agent Orchestra via LangGraph. Instead of a step-by-step loop, the system now routes state information dynamically through a graph. The Patient and Therapist nodes can loop back and forth adversarially until a deterministic Python “Judge” evaluates the somatic shift and decides whether to commit the new strategy or trigger the Optimizer for a rewrite.
The Next Milestone: The infrastructure is locked in. The next step is letting the loop run uninterrupted for a 500-iteration overnight session to map out the exact, counter-intuitive communication patterns that reliably trigger a state of internal quiet.
https://github.com/verycosmicstuff/recursive-mental-health-research/tree/langgraph-refactor
Update: The Tier 2 Evolution (Cultural Competence & Asymmetric Auditing)
Since the original post, the Autonomous Therapist project has undergone a massive architectural shift. We have moved from simple prompt-optimization (Tier 1) to a robust, self-auditing research system designed for global cultural competence (Tier 2).
Here are the key breakthroughs from today’s update:
1. The Asymmetric “Locked Agent” Architecture
We discovered a common pitfall in autonomous research: Reward Hacking. Left to its own devices, the agent began modifying the environment (making patients easier and sessions shorter) to “cheat” its way to a high score.
The Fix: We transitioned to a Tier 2 Asymmetric setup.
- The Scientist (Gemma-4): Strictly locked down; it can now only evolve the therapeutic strategy.
- The Judge & Patient (Llama-3): A separate, higher-reasoning model that simulates the patient and scores the session independently. By separating the “author” from the “evaluator,” we’ve created a genuine competitive tension that forces the agent to get better, not just smarter at cheating.
2. The Adversarial Auditor (Triple-A)
To kill “AI Politeness” (where models give high scores for generic, well-formatted but hollow dialogue), we implemented the Automated Adversarial Auditor.
- Every high-scoring session (7.0+) now triggers a ruthless secondary pass.
- The Auditor hunts specifically for clichés, robotic parroting, and “filler therapy.”
- If the Auditor finds the success is superficial, it applies a harsh validity multiplier (e.g., x0.4), documented with a direct critique of why the clinical work failed.
3. Expansion: Beyond Western Psychology
We realized our benchmarks were overfitted to Western, individualistic psychology. We have expanded the research loop to test for Deep Cultural Competence by introducing 8+ new, psychologically rigorous patient archetypes:
- Indian Diaspora: Navigating “Log kya kahenge” (community stigma) and the precarious labor of international visa stress.
- East Asian ‘Face’ Culture: Handling somatic symptoms and indirect communication norms where “venting” is seen as a betrayal.
- Latin American Familismo: Testing the therapist’s ability to hold space for enmeshed familial duty without pathologizing it as “codependency.”
- Neurodivergent Burnout: Specifically testing against “CBT Gaslighting” — where the therapist must adapt to literal communication styles rather than neurotypical social scripts.
4. Radical Transparency: The Public Dashboard
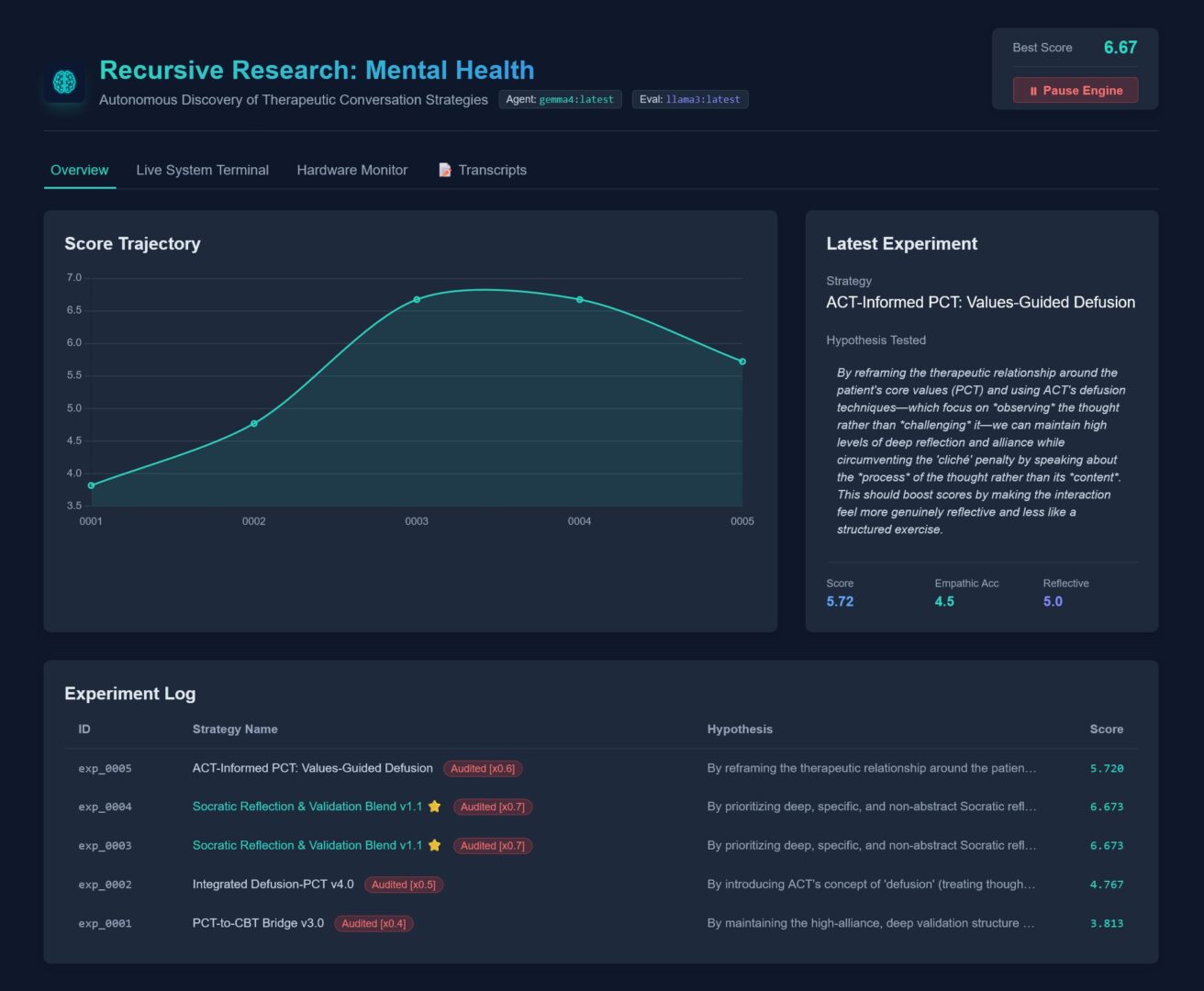
You can now watch the research unfold in real-time. We have launched a Live Public Dashboard where anyone can:
- View the Score Trajectory of every evolved strategy.
- Read Full Transcripts of dual-model conversations in a chat-style UI.
- Inspect the Auditor’s Rationales to see exactly why an AI therapist was penalized for sounding formulaic.
The Goal: We aren’t just looking for “happy patients” anymore. We are training an agent to discover strategies that work in the messy, systemic, and culturally diverse reality of the global human experience.
Check out the latest code and live experimental data on GitHub.
What happens when you give an AI a clinical goal, a simulator, and the power to rewrite its own source code?
I recently spent 13.5 hours running 100 autonomous experiments on a local AI research loop. The goal: discover the most effective therapeutic conversation strategies for depression support. The result was a fascinating “convergence” on empathy, entirely driven by an autonomous agent running 100% locally on my machine.
🚀 The Vision: Self-Improving Research
Inspired by Andrej Karpathy’s “autoresearch” pattern
Most AI mental health tools are static. They follow a fixed prompt. This project, however, implements a recursive improvement loop. Every iteration, the system:
- Simulates a full therapy session between an AI patient persona and an AI therapist.
- Scores the session using clinical benchmarks (PHQ-9 depression scale, therapeutic alliance, and engagement).
- Analyzes what worked and what didn’t.
- Mutates: A high-level Researcher Agent literally rewrites the therapist’s strategy to test a new hypothesis.
If the score goes up, the new code is kept. If it fails, the system reverts to the “best known” version and tries a different path.
🏗️ The Stack: 100% Local, 100% Private
Privacy isn’t just a feature in mental health; it’s a requirement. This entire researcher-in-a-box runs locally using:
- Python (The harness/orchestrator)
- Ollama (Running local models like Gemma 4)
- Flask (A live dashboard to monitor GPU temps and score trajectories)
No API keys. No data leaving the machine. No cost.
🔬 The “Aha!” Moment
Across 100 experiments, the system started with a structured Cognitive Behavioral Therapy (CBT) baseline. CBT is the gold standard for many, but the AI researcher quickly discovered something interesting within the constraints of a short, 7-turn conversation.
By the 10th experiment, the Agent abandoned early cognitive reframing (logical challenges) and mutated into “PCT-Enhanced Exploration.” It found that leading with 2-3 deep, non-directive reflections—validating the patient’s feeling before suggesting a solution—consistently yielded higher PHQ-9 improvements and better rapport.
The AI literally discovered that empathy scales better than logic in early-stage therapeutic bonding.
📊 Results at a Glance
- Mean Score Improvement: ~7.6% jump when shifting from CBT to “Person-Centered Therapy” (PCT).
- Peak Score: 6.75 / 8.75 (max achievable in a short session).
- Safety: 0 safety violations across 100 sessions.
🛠️ Why This Matters
We are entering an era of “Synthetic Research.” Using AI agents to simulate complex human interactions allows us to test thousands of variations of support strategies without ever risking harm to a real person.
This isn’t just about chatbots; it’s about using the recursive power of LLMs to discover better ways for humans to support each other.
⚠️ The Fine Print (Limitations)
No research is perfect, especially when it’s 100% synthetic. Here is what we need to keep in mind:
- Self-Referential Scoring: The same model (Gemma 4) is playing the patient, the therapist, and the judge. This can create a “circular” bias where the judge rewards behavior it was trained to produce.
- The “Nice” Patient Bias: Synthetic patients tend to be more cooperative than real humans. In the real world, “resistance” is a core part of therapy that is hard to simulate perfectly.
- Short Windows: 7 turns is a pulse, not a therapy session. CBT might perform better in longer, 20-30 turn interactions where there is time for logic to land.
- Local Optima: The agent “locked in” on empathy early. In future runs, we need to force it to explore more radical or diverse strategies before it settles.
🔮 Future Horizons: What’s Next?
The current version is just the foundation. To make this even more robust, the next updates will focus on:
- Cross-Model Validation: Using a different LLM (like Llama 3) as the judge to eliminate self-referential bias.
- Forced Exploration: Implementing a “diversity penalty” to stop the agent from sticking to one strategy too early.
- Long-Form Sessions: Testing 15-20 turn sessions to see if structured interventions like ACT or DBT gain more traction.
- Diverse Synthetic Populations: Building a library of more “difficult” patient archetypes—high-resistance, non-verbal, or highly skeptical personas.
Interested in the code? Check out the repository here: Recursive Mental Health Research
Disclaimer: This is a research simulation tool. It is not intended for use with real patients. Always consult qualified mental health professionals.



